关于 TCP, 我学到什么
TCP 在不可靠的 IP 协议之上实现了可靠性,使得我们在开发上层应用时,不必关注网络传输的种种复杂性。可靠,指的是采用一系列技术来保障数据在发送方和接收方是一致的。我们了解下 TCP 如何实现可靠性。
信道不可靠
需要解决的问题是,数据在信道上传输时,不总是符合预期,例如出现以下情况:
- 损坏:发送 10,11,接收到 10,10
- 乱序:发送 10,11,接收到 11,10
- 丢失:发送 10,11,只接收到 10
- ……
我们看 TCP 是怎么解决这些问题的,学习它的做法,这可以作为一类问题的处理思路。
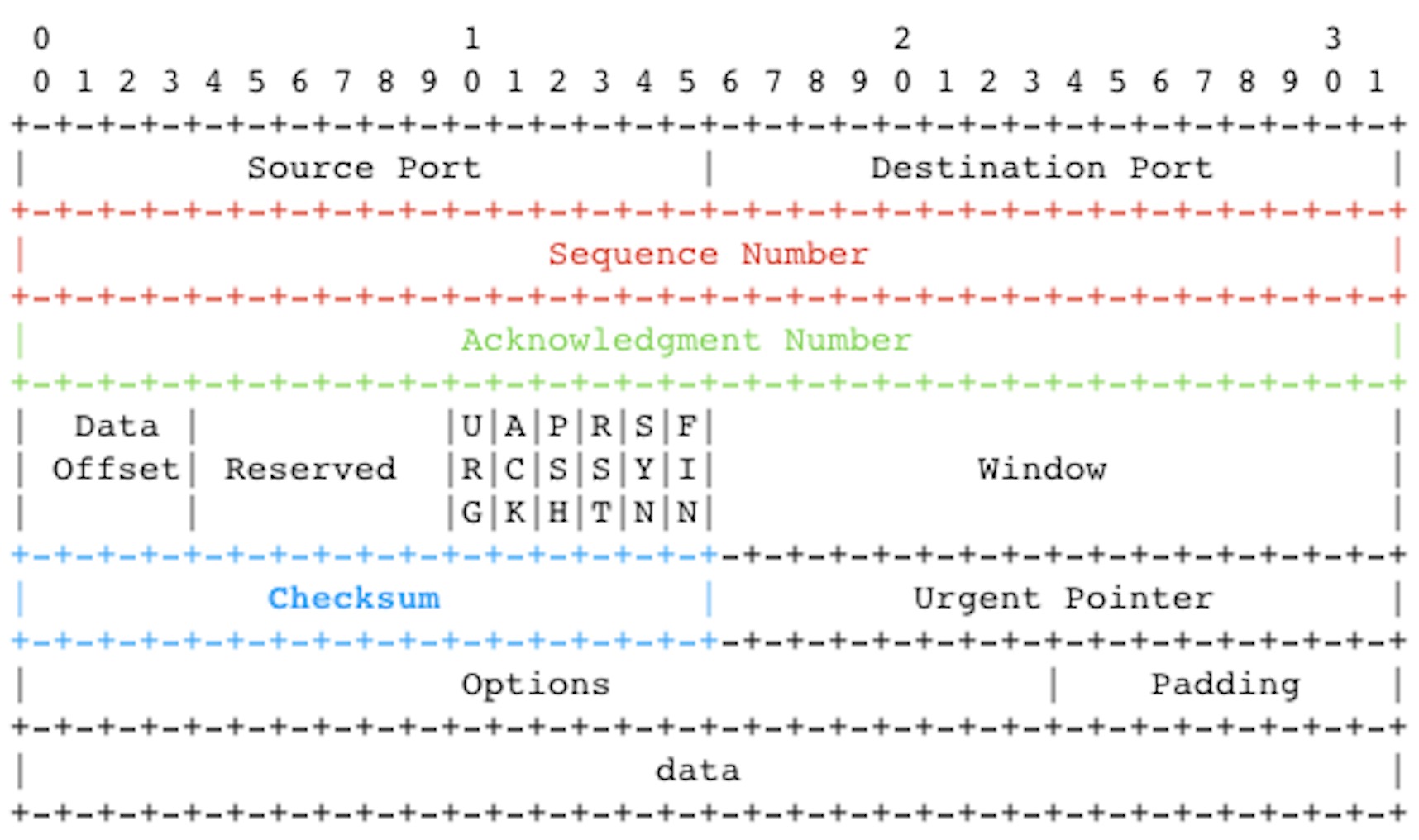
解决问题的办法其实写在了 TCP 报文头上,下面具体分析:
数据损坏
-
检验和机制:
Checksum用于校验报文是否在传输过程中发生了变化,计算方法:- 1.将报文中的
Checksum置零 - 2.基于整个报文(头部 + 数据部分)计算出
Checksum
- 1.将报文中的
接收方收到报文后,计算出 Checksum 并与报文中的 Checksum 对比。若一致,数据没有损坏。不一致,数据损坏,丢掉数据包。
乱序和冗余
- 字节编号机制:建立连接时,发送方和接收方各自初始化一个
seq(Seq...)值,并且让对方知道,这就是为什么 TCP 连接时需要三次握手。发送方每次发送数据,都是在自己前一次的seq值上加本报文的data字节数,得到本报文的seq值。接收方接收到多个报文后,按seq的值对所有数据包进行升序排列,就能得到有序的报文。并且接收方可以判断接收的数据包之间是否有间隔或冗余。
数据丢失
-
确认应答机制:接收方收到发送方的报文后,将
ack(Ack)传递给对方,ack的值表示接收方期望收到的下一次seq值。ack的计算与发送方报文的ack,ACK无关(对"确认"进行再确认无意义,在不可靠的信道上,双方不可能达成一致性确认,两军问题 ),这下再看 TCP 三次握手的图就清晰多了。 -
超时重传机制:报文在信道中丢失了,发送方就收不到对方的
ack。发送方在发送报文后,启用定时器(RTO)。一定时间没有返回就重传报文,就要知道报文在两方的往返时间(RTT),根据RTT设计RTO。而RTT实际上是波动的,当RTO < RTT时,就造成了数据冗余。 -
快速重传机制:以数据驱动重传,例如发送方发送了
seq=1、seq=2、seq=3、seq=4的报文,其中seq=1的报文丢失了,发送方会收到三个连续的ack=1,此时就触发快速重传机制,重传seq=1。
基本可靠
上面的设计在简单场景中是基本可靠的,即确保了字节流在通信双方完全相同。在复杂的场景中,TCP 还有很多其他的机制来实现可靠性。例如,造成数据丢失的原因有很多:
-
发送方对数据的处理效率高于接收方,接收方达到处理能力极限,而发送方无法感知,依然大量传递数据,就造成了数据丢失。(流量太快)
-
发送太多的数据造成数据在信道中过于拥堵,也会造成数据丢失。(流量太多)
这两种情况都会触发 TCP 的重传机制,而重传只会丢失更多数据,应对这两种情况,我们需要更多的机制:
-
流量控制机制:找到 TCP 两方中效率低的一方一次能处理的数据峰值,用
Window表示,发送方根据Window的大小发送数据包,直到接收方收到所有数据包再进行下一次数据发送。 -
拥塞控制机制:找到信道一次能容纳的数据峰值,具体的实现涉及很多复杂的算法。
可靠性其实是一个很大的话题,有很多细节值得深究,本文只是让读者对可靠性有个基本的认识。
参阅资料